介绍
通过反射把 ShaderLab代码生成OpenGL ES着色器代码,会利用OpenGL ES 代码模拟在ARM GPU 架构下的性能表现主要是代码复杂度(如运算)已经相应的指令和优化建议Bound,以下默认是Mali-G710(天玑9000)作为模拟环境(基于ARM Mali Offline Compiler) 解析生成的数据。桌面GUI软件基于WPF实现,为Shader优化提供参考指标
使用
Unity 内导入该扩展SDK,选中Shader文件(确保不是URP管线和HDRP管线Shader) 右键AnalyseShader即可
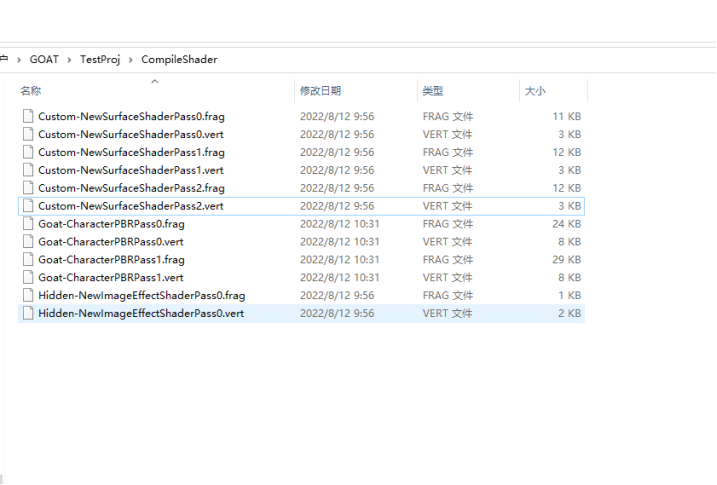
生成的中间临时目录(Assets目录同级下CompileShader目录),每个Pass分别会生成OpenGL ES的顶点和片段着色器代码,中途会自动打开编辑器因为反射调用了Editor内部代码,内部调用了内核的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| private static string CompileShader(Shader shader)
{
ParseList.Clear();
CurShader = shader;
if (DebugToggle)
{
Debug.Log($"ShaderInspectorPlatformMode >> {EditorPrefs.GetInt("ShaderInspectorPlatformMode", 1)}");
Debug.Log($"ShaderInspectorPlatformMask >> {EditorPrefs.GetInt("ShaderInspectorPlatformMask", 1)}");
Debug.Log($"ShaderInspectorVariantStripping >> {EditorPrefs.GetInt("ShaderInspectorVariantStripping", 1)}");
}
string winTitle = $"{GetSlnName()} - Microsoft Visual Studio";
var POpenCompiledShader = mAssembly.GetType("UnityEditor.ShaderUtil").GetMethod("OpenCompiledShader", Binding);
POpenCompiledShader.Invoke(null, new object[4] { shader, 3, 512, false });
if (!OpenToggle) WinExtension.WindowMin(winTitle);
string compilePath = Application.dataPath + "/../Temp/Compiled-" + shader.name.Replace("/", "-") + ".shader";
status = ShaderAnalyseStatus.Analyse;
return compilePath;
}
|
因为导出结果没有固定规则的,所以需要自己手动去解析,这里单独实现了一个非规则数据的解析库,局部参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| public class ShaderCompileProgram : BaseProgram
{
public override async Task OnStart(params object[] args)
{
base.OnStart(args);
int findStartIndex = -1;
int findEndIndex = -1;
int passCount = 0;
var status = await System.Execute<LineFindCountRule>((object[] o) =>
{
var getVal = (int)o[0];
if (getVal > 0) passCount = getVal;
}, " Pass {");
Debug.Log(passCount);
for (int index = 0; index < passCount; index++)
{
status = await System.ExecuteUntilSuccess<LineFintStartRule>((object[] o) =>
{
var getVal = (int)o[0];
if (getVal != -1) findStartIndex = getVal + 1;
}, "#ifdef VERTEX", "#version 300 es");
status = await System.ExecuteUntilSuccess<LineFintStartRule>((object[] o) =>
{
var getVal = (int)o[0];
if (getVal != -1) findEndIndex = getVal - 1;
}, "#endif", "#ifdef FRAGMENT");
string[] subVertexArray = new string[findEndIndex - findStartIndex];
Array.Copy(this.System.lines, findStartIndex, subVertexArray, 0, findEndIndex - findStartIndex);
findStartIndex = -1;
findEndIndex = -1;
status = await System.ExecuteUntilSuccess<LineFintStartRule>((object[] o) =>
{
var getVal = (int)o[0];
if (getVal != -1) findStartIndex = getVal + 1;
}, "#ifdef FRAGMENT", "#version 300 es");
status = await System.ExecuteUntilSuccess<FindPreNotEqualRule>("-- Hardware tier variant", "Local Keywords: <none>", "Global Keywords: <none>");
if (status) findEndIndex = System.CurLineIndex - 3;
Debug.Log("findEndIndex" + findEndIndex);
Debug.Log("findStartIndex" + findStartIndex);
string[] subFragmentArray = new string[findEndIndex - findStartIndex];
Array.Copy(this.System.lines, findStartIndex, subFragmentArray, 0, findEndIndex - findStartIndex);
System.FinishProgram(new object[3] { index, subVertexArray, subFragmentArray });
}
}
public override void Exit()
{
base.Exit();
}
public override void Load(RuleSystem system)
{
base.Load(system);
}
public override void UnLoad()
{
base.UnLoad();
}
|
桌面端基本就数据解析,控件绑定,更新同步,安装包封包
ARM Mali Offline Compiler相关指令作用参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| Uniform registers
一个只读寄存器,用于存储着色器可能需要的常量及时间常量。
Stack spilling
对于Valhall 和 Bifrost GPUs,可以看到是否有变量被放置到栈内存中。放置到栈中的内存对于GPU读取是性能消耗较大的。
16-bit arithmetic
以 16 位或更低精度执行的算术运算的百分比,只计算纯算术指令(不包括插值、纹理和混合),这个着色器很少。我们也只计算完全是 16 位的指令(16 位输入、16 位数据处理、16 位输出)。丢弃指令 discard 只有一个 32 位数据路径,因此将包括 16 位输入的隐式扩展。这对性能没有影响,但确实意味着它不会出现在统计数据中,一些内置函数只有 32 位数据路径。尽管我为他们提供了 16 位参数,但他们仍然将它们作为 32 位参数处理
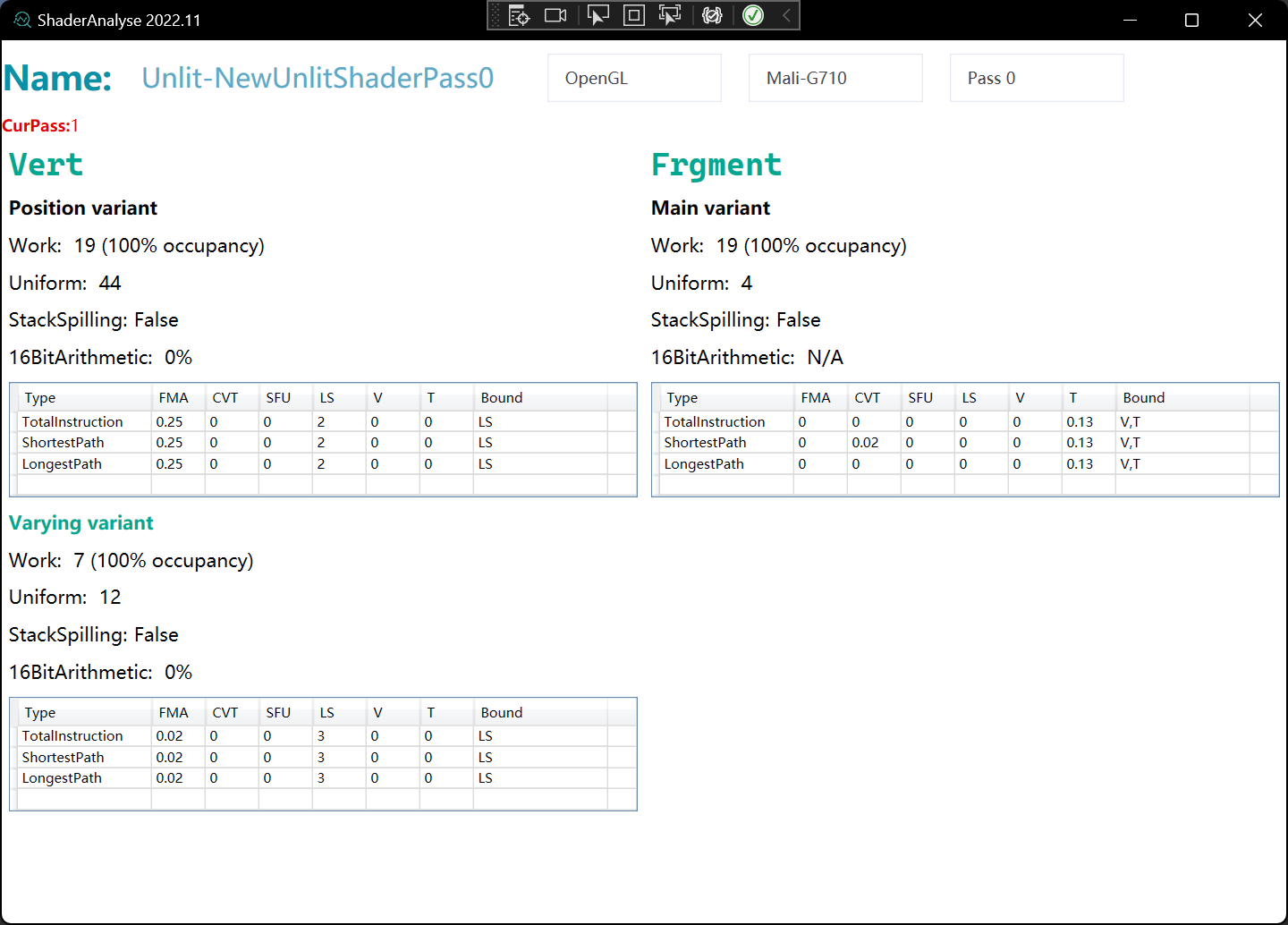
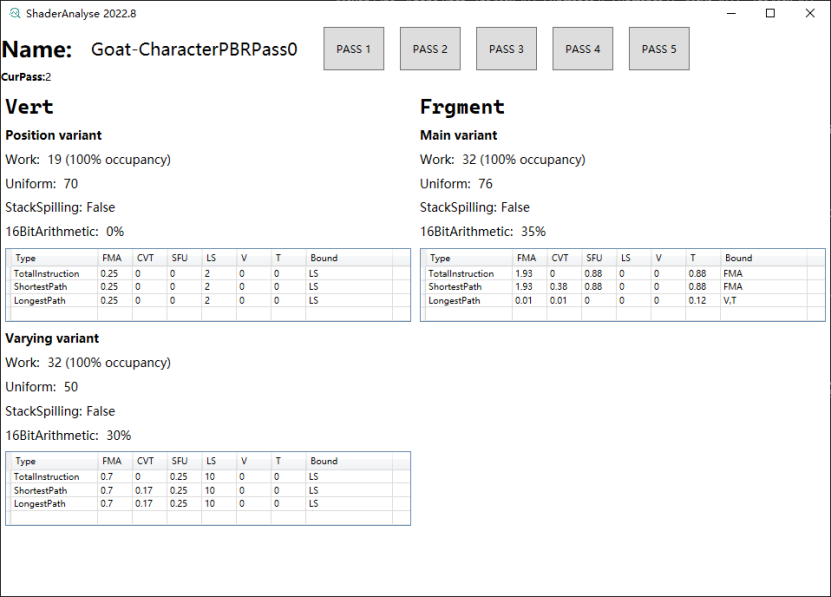
Shader信息
Total Instruction Cycles
为程序生成的所有指令的累积执行周期数,与程序控制流无关。
Shortest Path Cycles
通过着色器程序的最短控制流路径的循环数的估计。该行根据设计中存在的功能单元数量对周期成本进行标准化。
Longest Path Cycles
通过着色器程序的最长控制流路径的循环数的估计。该行根据设计中存在的功能单元数量对周期成本进行标准化。并非总是可以根据静态分析确定最长路径
A = Arithmetic operations
数学运算操作符。具体代表了shader中sum multiply等操作
FMA Fused multiply accumulate
加减乘除运算符
CVT Arithmetic conversion
算术转换操作符
SFU Special functions unit
特殊功能单元
LS = Load/Store operation
读取和存储的操作
V = Varying operations
在shader中不同单位插值的消耗
T = Texture operations
采样贴图的消耗
|
参考资料
https://developer.arm.com/Tools%20and%20Software/Mali%20Offline%20Compiler